

Teste clássico: Um experimento psicológico criado há décadas revelou falhas surpreendentes na capacidade de foco dos sistemas mais avançados do mundo.
Queda de desempenho: À medida que a complexidade das listas aumentava, a precisão das respostas de modelos de última geração desabava drasticamente.
Limite dos transformadores: O estudo indica que os mecanismos de atenção digital diferem fundamentalmente dos sistemas cognitivos humanos.
O avanço dos sistemas baseados em redes neurais impressiona o mundo pela capacidade de resolver problemas complexos, gerar códigos e manter conversações. No entanto, um estudo recente conduzido por pesquisadores revelou que até as ferramentas mais sofisticadas possuem uma vulnerabilidade inesperada quando submetidas a exames tradicionais da psicologia. Ao testar a resiliência dessas ferramentas diante de estímulos conflitantes por períodos prolongados, os cientistas descobriram que a atenção computacional opera de forma distinta do foco biológico, falhando em tarefas básicas de controle executivo que humanos realizam com facilidade.
Como o teste de Stroop desafia a inteligência artificial?
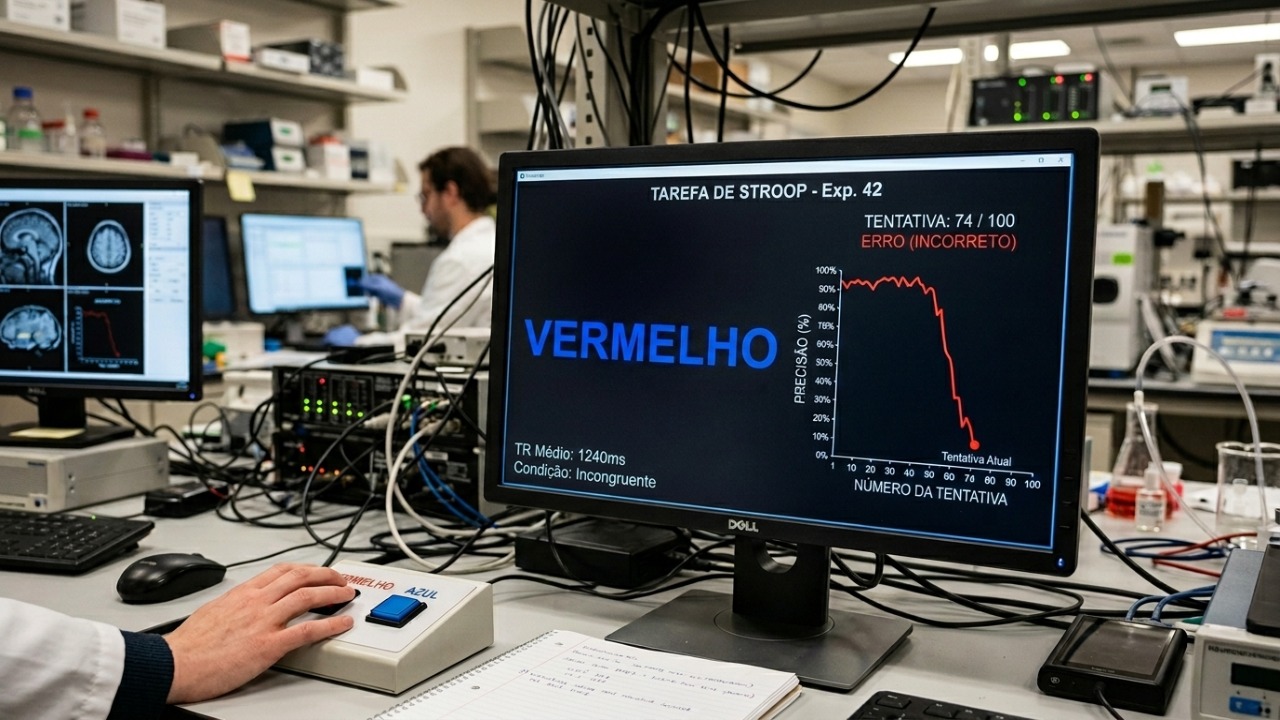
O famoso experimento psicológico consiste em exibir palavras que nomeiam cores escritas em tons de tinta que podem ou não coincidir com o significado textual. A grande dificuldade surge quando há um descompasso, como a palavra “vermelho” escrita na cor azul, exigindo que o participante ignore a leitura automática e identifique apenas a cor visual da tinta. Essa dinâmica gera um conflito mental que demanda o controle executivo do cérebro para suprimir o impulso de ler.
Enquanto as pessoas mantêm alto nível de acerto em testes longos, os sistemas digitais apresentaram um comportamento diferente. Os cientistas avaliaram os principais modelos de linguagem e constataram que, diante de desafios com maior volume de dados, essas ferramentas começam a cometer erros primários. Os principais fatores analisados durante os experimentos incluíram os seguintes aspectos:
- A extensão total das listas de termos apresentadas.
- O nível de conflito entre o significado e a cor.
- A presença simultânea de itens condizentes e divergentes.
Qual foi o desempenho dos principais modelos do mercado?
Nos testes aplicados com listas curtas contendo cinco palavras confusas, as ferramentas digitais mostraram um excelente desempenho técnico. O modelo mais recente da OpenAI atingiu marcas elevadas de precisão, enquanto outros concorrentes também demonstraram forte capacidade de processamento imediato. Essa resposta trouxe uma falsa impressão de que as máquinas conseguiam de fato superar as distrações textuais impostas pela dinâmica do exame.
A situação mudou de figura de maneira drástica conforme o tamanho do desafio aumentava progressivamente para os sistemas. Os pesquisadores notaram quedas acentuadas de eficiência em plataformas renomadas, que demonstraram colapsos severos de desempenho estrutural, conforme detalhado a seguir:
- A taxa de acerto do GPT-4o desabou de noventa e um por cento para apenas quinze por cento.
- O Claude 3.5 Sonnet resistiu até listas médias, mas despencou para vinte e quatro por cento de precisão.
- Sistemas inovadores como o GPT-5 e o Gemini 2.5 registraram padrões semelhantes de falha generalizada.
Por que a precisão despenca em listas longas?
A pesquisa demonstrou que o colapso nas respostas ocorre porque as ferramentas de processamento linguístico perdem o rastro do objetivo original ao longo do tempo. Conforme as sequências avançam, os modelos de linguagem passam a ignorar as instruções iniciais e revertem para a leitura automatizada das palavras. Esse comportamento fica ainda pior se elementos compatíveis e incompatíveis forem misturados na mesma sequência, reduzindo a precisão das respostas a quase zero.
Esse declínio acentuado evidencia uma incapacidade de sustentar o foco sob condições de estresse informacional continuado. Ao contrário dos seres humanos, que aplicam uma energia cognitiva direcionada para resistir aos impulsos, o mecanismo computacional acaba sendo esmagado pelo peso do seu próprio treinamento massivo voltado para a interpretação de textos.
Quais são as diferenças entre o foco humano e o digital?
Tanto as pessoas quanto os algoritmos avançados recebem muito mais treinamento voltado para reconhecer palavras do que para identificar tonalidades visuais isoladas. No entanto, a mente humana possui sistemas biológicos refinados que permitem inibir respostas automáticas e manter metas de longo prazo ativas na memória. Os transformadores que sustentam a arquitetura dos modelos antigos e atuais operam por cálculos estatísticos que funcionam de maneira diversa.
O estudo aponta que essa divergência estrutural impede que os algoritmos resolvam conflitos cognitivos com a mesma resiliência de um operador humano. Os principais pontos que diferenciam a cognição biológica dos mecanismos artificiais de atenção revelados pela investigação abrangem os itens listados abaixo:
- A habilidade humana de manter instruções ativas por longos períodos.
- O isolamento eficiente de estímulos puramente visuais sobre textos.
- A presença de um controle executivo central nos cérebros biológicos.

O que essa falha revela sobre as limitações da automação?
Os resultados trazem uma reflexão profunda sobre a verdadeira natureza das ferramentas de conversação e raciocínio lógico que utilizamos diariamente. Embora essas plataformas demonstrem habilidades impressionantes em tarefas de escrita, programação e análise de dados, o experimento prova que alto desempenho não significa processamento idêntico ao humano. Existem fraquezas cognitivas ocultas nas estruturas de inteligência artificial que surgem justamente quando há necessidade de foco sustentado.
Compreender esses limites operacionais torna-se um fator indispensável à medida que a automação avança sobre setores essenciais da sociedade moderna. Mapear onde os sistemas falham permite que engenheiros e usuários desenvolvam estratégias de integração mais seguras, evitando delegar decisões críticas a mecanismos que podem simplesmente perder a concentração diante de cenários longos e repetitivos.
Referências: “Deficient executive control in transformer attention”, dos autores Suketu Chandrakant Patel, Hongbin Wang e Jin Fan, publicado na revista PNAS Nexus.
